

“Things take longer to happen than you think they will, and then they happen faster than you thought they could.” - Rudiger Dornbusch
I’ve had a lot of discussions on my podcast where we haggle out timelines to AGI. Some guests think it’s 20 years away - others 2 years. Here’s where my thoughts stand as of June 2025.
Continual learning
Sometimes people say that even if all AI progress totally stopped, the systems of today would still be far more economically transformative than the internet. I disagree. I think the LLMs of today are magical. But the reason that the Fortune 500 aren’t using them to transform their workflows isn’t because the management is too stodgy. Rather, I think it’s genuinely hard to get normal humanlike labor out of LLMs. And this has to do with some fundamental capabilities these models lack.
I like to think I’m “AI forward” here at the Dwarkesh Podcast. I’ve probably spent over a hundred hours trying to build little LLM tools for my post production setup. And the experience of trying to get them to be useful has extended my timelines. I’ll try to get the LLMs to rewrite autogenerated transcripts for readability the way a human would. Or I’ll try to get them to identify clips from the transcript to tweet out. Sometimes I’ll try to get them to co-write an essay with me, passage by passage. These are simple, self contained, short horizon, language in-language out tasks - the kinds of assignments that should be dead center in the LLMs’ repertoire. And they're 5/10 at them. Don’t get me wrong, that’s impressive.
But the fundamental problem is that LLMs don’t get better over time the way a human would. The lack of continual learning is a huge huge problem. The LLM baseline at many tasks might be higher than an average human's. But there’s no way to give a model high level feedback. You’re stuck with the abilities you get out of the box. You can keep messing around with the system prompt. In practice this just doesn’t produce anything even close to the kind of learning and improvement that human employees experience.
The reason humans are so useful is not mainly their raw intelligence. It’s their ability to build up context, interrogate their own failures, and pick up small improvements and efficiencies as they practice a task.
How do you teach a kid to play a saxophone? You have her try to blow into one, listen to how it sounds, and adjust. Now imagine teaching saxophone this way instead: A student takes one attempt. The moment they make a mistake, you send them away and write detailed instructions about what went wrong. The next student reads your notes and tries to play Charlie Parker cold. When they fail, you refine the instructions for the next student.
This just wouldn’t work. No matter how well honed your prompt is, no kid is just going to learn how to play saxophone from just reading your instructions. But this is the only modality we as users have to ‘teach’ LLMs anything.
Yes, there’s RL fine tuning. But it’s just not a deliberate, adaptive process the way human learning is. My editors have gotten extremely good. And they wouldn’t have gotten that way if we had to build bespoke RL environments for different subtasks involved in their work. They’ve just noticed a lot of small things themselves and thought hard about what resonates with the audience, what kind of content excites me, and how they can improve their day to day workflows.
Now, it’s possible to imagine some way in which a smarter model could build a dedicated RL loop for itself which just feels super organic from the outside. I give some high level feedback, and the model comes up with a bunch of verifiable practice problems to RL on - maybe even a whole environment in which to rehearse the skills it thinks it's lacking. But this just sounds really hard. And I don’t know how well these techniques will generalize to different kinds of tasks and feedback. Eventually the models will be able to learn on the job in the subtle organic way that humans can. However, it’s just hard for me to see how that could happen within the next few years, given that there’s no obvious way to slot in online, continuous learning into the kinds of models these LLMs are.
LLMs actually do get kinda smart and useful in the middle of a session. For example, sometimes I’ll co-write an essay with an LLM. I’ll give it an outline, and I’ll ask it to draft the essay passage by passage. All its suggestions up till 4 paragraphs in will be bad. So I'll just rewrite the whole paragraph from scratch and tell it, "Hey, your shit sucked. This is what I wrote instead." At that point, it can actually start giving good suggestions for the next paragraph. But this whole subtle understanding of my preferences and style is lost by the end of the session.
Maybe the easy solution to this looks like a long rolling context window, like Claude Code has, which compacts the session memory into a summary every 30 minutes. I just think that titrating all this rich tacit experience into a text summary will be brittle in domains outside of software engineering (which is very text-based). Again, think about the example of trying to teach someone how to play the saxophone using a long text summary of your learnings. Even Claude Code will often reverse a hard-earned optimization that we engineered together before I hit /compact - because the explanation for why it was made didn’t make it into the summary.
This is why I disagree with something Sholto and Trenton said on my podcast (this quote is from Trenton):
“Even if AI progress totally stalls (and you think that the models are really spiky, and they don't have general intelligence), it's so economically valuable, and sufficiently easy to collect data on all of these different white collar job tasks, such that to Sholto's point we should expect to see them automated within the next five years.”
If AI progress totally stalls today, I think <25% of white collar employment goes away. Sure, many tasks will get automated. Claude 4 Opus can technically rewrite autogenerated transcripts for me. But since it’s not possible for me to have it improve over time and learn my preferences, I still hire a human for this. Even if we get more data, without progress in continual learning, I think we will be in a substantially similar position with white collar work - yes, technically AIs might be able to do a lot of subtasks somewhat satisfactorily, but their inability to build up context will make it impossible to have them operate as actual employees at your firm.
While this makes me bearish on transformative AI in the next few years, it makes me especially bullish on AI over the next decades. When we do solve continuous learning, we’ll see a huge discontinuity in the value of the models. Even if there isn’t a software only singularity (with models rapidly building smarter and smarter successor systems), we might still see something that looks like a broadly deployed intelligence explosion. AIs will be getting broadly deployed through the economy, doing different jobs and learning while doing them in the way humans can. But unlike humans, these models can amalgamate their learnings across all their copies. So one AI is basically learning how to do every single job in the world. An AI that is capable of online learning might functionally become a superintelligence quite rapidly without any further algorithmic progrss
However, I’m not expecting to watch some OpenAI livestream where they announce that continual learning has been totally solved. Because labs are incentivized to release any innovations quickly, we’ll see a broken early version of continual learning (or test time training - whatever you want to call it) before we see something which truly learns like a human. I expect to get lots of heads up before this big bottleneck is totally solved.
Computer use
When I interviewed Anthropic researchers Sholto Douglas and Trenton Bricken on my podcast, they said that they expect reliable computer use agents by the end of next year. We already have computer use agents right now, but they’re pretty bad. They’re imagining something quite different. Their forecast is that by the end of next year, you should be able to tell an AI, “Go do my taxes.” And it goes through your email, Amazon orders, and Slack messages, emails back and forth with everyone you need invoices from, compiles all your receipts, decides which are business expenses, asks for your approval on the edge cases, and then submits Form 1040 to the IRS.
I’m skeptical. I’m not an AI researcher, so far be it for me to contradict them on technical details. But given what little I know, here’s why I’d bet against this forecast:
As horizon lengths increase, rollouts have to become longer. The AI needs to do two hours worth of agentic computer use tasks before we can even see if it did it right. Not to mention that computer use requires processing images and video, which is already more compute intensive, even if you don’t factor in the longer rollout. This seems like this should slow down progress.
We don’t have a large pretraining corpus of multimodal computer use data. I like this quote from Mechanize’s post on automating software engineering: “For the past decade of scaling, we’ve been spoiled by the enormous amount of internet data that was freely available for us to use. This was enough for cracking natural language processing, but not for getting models to become reliable, competent agents. Imagine trying to train GPT-4 on all the text data available in 1980—the data would be nowhere near enough, even if we had the necessary compute.”
Again, I’m not at the labs. Maybe text only training already gives you a great prior on how different UIs work, and what the relationship between different components is. Maybe RL fine tuning is so sample efficient that you don’t need that much data. But I haven’t seen any public evidence which makes me think that these models have suddenly gotten less data hungry, especially in this domain where they’re substantially less practiced.
Alternatively, maybe these models are such good front end coders that they can just generate millions of toy UIs for themselves to practice on. For my reaction to this, see bullet point below.
Even algorithmic innovations which seem quite simple in retrospect seem to take a long time to iron out. The RL procedure which DeepSeek explained in their R1 paper seems simple at a high level. And yet it took 2 years from the launch of GPT-4 to the release of o1. Now of course I know it is hilariously arrogant to say that R1/o1 were easy - a ton of engineering, debugging, pruning of alternative ideas was required to arrive at this solution. But that’s precisely my point! Seeing how long it took to implement the idea, ‘Train the model to solve verifiable math and coding problems’, makes me think that we’re underestimating the difficulty of solving the much gnarlier problem of computer use, where you’re operating in a totally different modality with much less data.
Reasoning
Okay, enough cold water. I’m not going to be like one of those spoiled children on Hackernews who could be handed a golden-egg laying goose and still spend all their time complaining about how loud its quacks are.
Have you read the reasoning traces of o3 or Gemini 2.5? It’s actually reasoning! It’s breaking down a problem, thinking through what the user wants, reacting to its own internal monologue, and correcting itself when it notices that it's pursuing an unproductive direction. How are we just like, “Oh yeah of course the machine is gonna go think a bunch, come up with a bunch of ideas, and come back with a smart answer. That’s what machines do.”
Part of the reason some people are too pessimistic is that they haven’t played around with the smartest models operating in the domains that they’re most competent in. Giving Claude Code a vague spec and sitting around for 10 minutes until it zero shots a working application is a wild experience. How did it do that? You could talk about circuits and the training distribution and RL and whatever, but the most proximal, concise, and accurate explanation is simply that it’s powered baby general intelligence. At this point, part of you has to be thinking, “It’s actually working. We’re making machines that are intelligent.”
So what are my predictions?
My probability distributions are super wide. And I want to emphasize that I do believe in probability distributions. Which means that work to prepare for misaligned 2028 ASI still makes a lot of sense - I think this is a totally plausible outcome.
But here are the timelines where I’d take a 50/50 bet:
AI can do taxes end-to-end for my small business as well as a competent general manager could in a week: including chasing down all the receipts on different websites, finding all the missing pieces, emailing back and forth with anyone we need to hassle for invoices, filling out the form, and sending it to the IRS: 2028
I think we’re in the GPT 2 era for computer use. But we have no pretraining corpus, and the models are optimizing for a much sparser reward over a much longer time horizon using action primitives they’re unfamiliar with. That being said, the base model is decently smart and might have a good prior over computer use tasks, plus there’s a lot more compute and AI researchers in the world, so it might even out. Preparing taxes for a small business feels like for computer use what GPT 4 was for language. It took 4 years to get from GPT 2 to GPT 4.
Just to clarify, I am not saying that we won’t have really cool computer use demos in 2026 and 2027 (GPT-3 was super cool, but not that practically useful). I’m saying that these models won’t be capable of end-to-end handling a week long and quite involved project which involves computer use.
AI learns on the job as easily, organically, seamlessly, and quickly as a human, for any white collar work. For example, if I hire an AI video editor, after six months, it has as much actionable, deep understanding of my preferences, our channel, what works for the audience, etc as a human would: 2032
While I don’t see an obvious way to slot in continuous online learning into current models, 7 years is a long time! GPT 1 had just come out this time 7 years ago. It doesn’t seem implausible to me that over the next 7 years, we’ll find some way for models to learn on the job.
You might react, “Wait you made this huge fuss about continual learning being such a handicap. But then your timeline is that we’re 7 years away from what would at minimum be a broadly deployed intelligence explosion.” And yeah, you’re right. I’m forecasting a pretty wild world within a relatively short amount of time.
AGI timelines are very lognormal. It's either this decade or bust. (Not really bust, more like lower marginal probability per year - but that’s less catchy).AI progress over the last decade has been driven by scaling training compute of frontier systems (over 4x a year). This cannot continue beyond this decade, whether you look at chips, power, even fraction of raw GDP used on training. After 2030, AI progress has to mostly come from algorithmic progress. But even there the low hanging fruit will be plucked (at least under the deep learning paradigm). So the yearly probability of AGI craters.
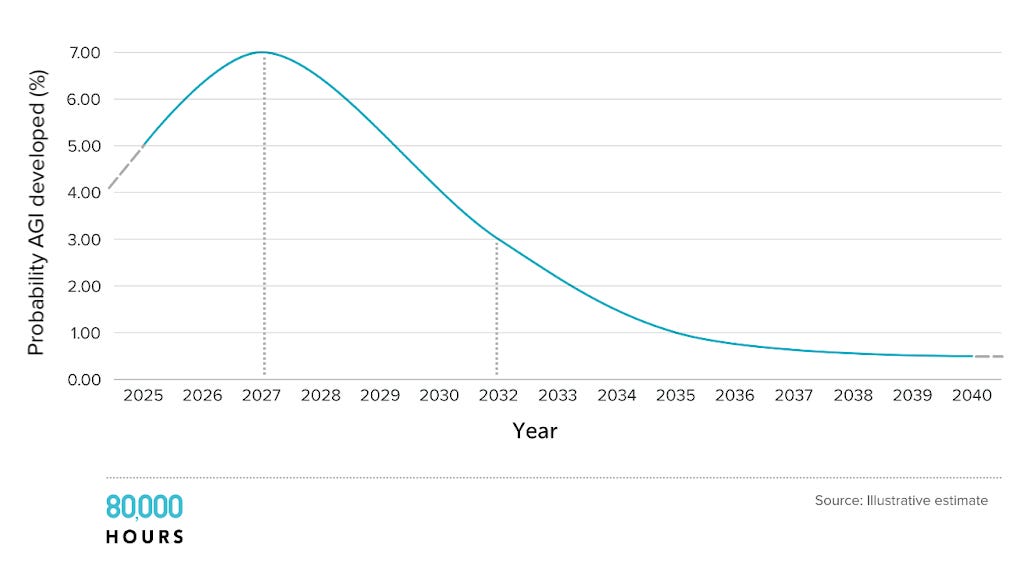
This means that if we end up on the longer side of my 50/50 bets, we might well be looking at a relatively normal world up till the 2030s or even the 2040s. But in all the other worlds, even if we stay sober about the current limitations of AI, we have to expect some truly crazy outcomes.
Great post! This is basically how I think about things as well. So why the difference in our timelines then?
--Well, actually, they aren't that different. My median for the intelligence explosion is 2028 now (one year longer than it was when writing AI 2027), which means early 2028 or so for the superhuman coder milestone described in AI 2027, which I'd think roughly corresponds to the "can do taxes end-to-end" milestone you describe as happening by end of 2028 with 50% probability. Maybe that's a little too rough; maybe it's more like month-long horizons instead of week-long. But at the growth rates in horizon lengths that we are seeing and that I'm expecting, that's less than a year...
--So basically it seems like our only serious disagreement is the continual/online learning thing, which you say 50% by 2032 on whereas I'm at 50% by end of 2028. Here, my argument is simple: I think that once you get to the superhuman coder milestone, the pace of algorithmic progress will accelerate, and then you'll reach full AI R&D automation and it'll accelerate further, etc. Basically I think that progress will be much faster than normal around that time, and so innovations like flexible online learning that feel intuitively like they might come in 2032 will instead come later that same year.
(For reference AI 2027 depicts a gradual transition from today to fully online learning, where the intermediate stages look something like "Every week, and then eventually every day, they stack on another fine-tuning run on additional data, including an increasingly high amount of on-the-job real world data." A janky unprincipled solution in early 2027 that gives way to more elegant and effective things midway through the year.)
I agree with much of this post. I also have roughly 2032 medians to things going crazy, I agree learning on the job is very useful, and I'm also skeptical we'd see massive white collar automation without further AI progress.
However, I think Dwarkesh is wrong to suggest that RL fine-tuning can't be qualitatively similar to how humans learn.
In the post, he discusses AIs constructing verifiable RL environments for themselves based on human feedback and then argues this wouldn't be flexible and powerful enough to work, but RL could be used more similarly to how humans learn.
My best guess is that the way humans learn on the job is mostly by noticing when something went well (or poorly) and then sample efficiently updating (with their brain doing something analogous to an RL update). In some cases, this is based on external feedback (e.g. from a coworker) and in some cases it's based on self-verification: the person just looking at the outcome of their actions and then determining if it went well or poorly.
So, you could imagine RL'ing an AI based on both external feedback and self-verification like this. And, this would be a "deliberate, adaptive process" like human learning. Why would this currently work worse than human learning?
Current AIs are worse than humans at two things which makes RL (quantitatively) much worse for them:
1. Robust self-verification: the ability to correctly determine when you've done something well/poorly in a way which is robust to you optimizing against it.
2. Sample efficiency: how much you learn from each update (potentially leveraging stuff like determining what caused things to go well/poorly which humans certainly take advantage of). This is especially important if you have sparse external feedback.
But, these are more like quantitative than qualitative issues IMO. AIs (and RL methods) are improving at both of these.
All that said, I think it's very plausible that the route to better continual learning routes more through building on in-context learning (perhaps through something like neuralese, though this would greatly increase misalignment risks...).
Some more quibbles:
- For the exact podcasting tasks Dwarkesh mentions, it really seems like simple fine-tuning mixed with a bit of RL would solve his problem. So, an automated training loop run by the AI could probably work here. This just isn't deployed as an easy-to-use feature.
- For many (IMO most) useful tasks, AIs are limited by something other than "learning on the job". At autonomous software engineering, they fail to match humans with 3 hours of time and they are typically limited by being bad agents or by being generally dumb/confused. To be clear, it seems totally plausible that for podcasting tasks Dwarkesh mentions, learning is the limiting factor.
- Correspondingly, I'd guess the reason that we don't see people trying more complex RL based continual learning in normal deployments is that there is lower hanging fruit elsewhere and typically something else is the main blocker. I agree that if you had human level sample efficiency in learning this would immediately yield strong results (e.g., you'd have very superhuman AIs with 10^26 FLOP presumably), I'm just making a claim about more incremental progress.
- I think Dwarkesh uses the term "intelligence" somewhat atypically when he says "The reason humans are so useful is not mainly their raw intelligence. It's their ability to build up context, interrogate their own failures, and pick up small improvements and efficiencies as they practice a task." I think people often consider how fast someone learns on the job as one aspect of intelligence. I agree there is a difference between short feedback loop intelligence (e.g. IQ tests) and long feedback loop intelligence and they are quite correlated in humans (while AIs tend to be relatively worse at long feedback loop intelligence).
- Dwarkesh notes "An AI that is capable of online learning might functionally become a superintelligence quite rapidly, even if there's no algorithmic progress after that point." This seems reasonable, but it's worth noting that if sample efficient learning is very compute expensive, then this might not happen so rapidly.
- I think AIs will likely overcome poor sample efficiency to achieve a very high level of performance using a bunch of tricks (e.g. constructing a bunch of RL environments, using a ton of compute to learn when feedback is scarce, learning from much more data than humans due to "learn once deploy many" style strategies). I think we'll probably see fully automated AI R&D prior to matching top human sample efficiency at learning on the job. Notably, if you do match top human sample efficiency at learning (while still using a similar amount of compute to the human brain), then we already have enough compute for this to basically immediately result in vastly superhuman AIs (human lifetime compute is maybe 3e23 FLOP and we'll soon be doing 1e27 FLOP training runs). So, either sample efficiency must be worse or at least it must not be possible to match human sample efficiency without spending more compute per data-point/trajectory/episode.
(I originally posted this on twitter (https://x.com/RyanPGreenblatt/status/1929757554919592008), but thought it might be useful to put here too.)